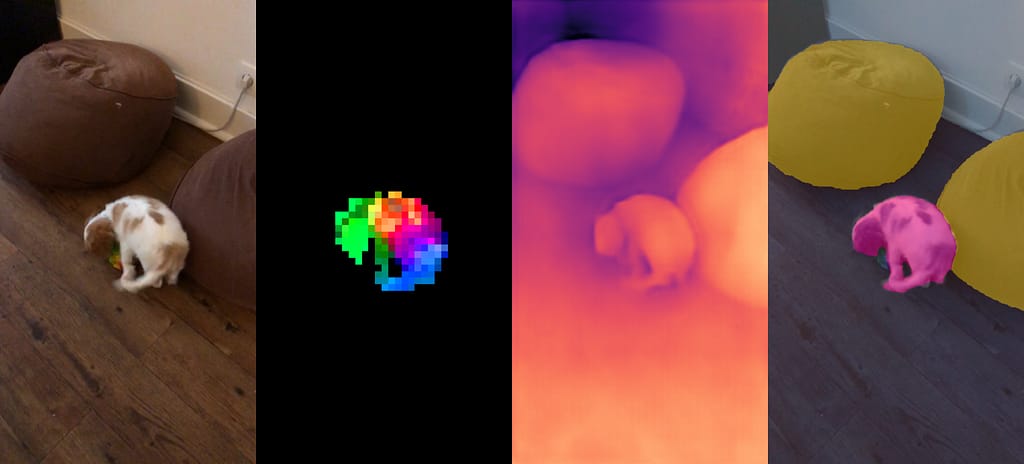
In the world of artificial intelligence and computer vision, self-supervised learning has emerged as a promising avenue for training neural networks without the need for labeled data. One fascinating development in this field is DINOv2, short for “Emerging Properties in Self-Supervised Vision Transformers.” This innovative approach, presented by researchers from Facebook AI Research, takes self-supervised learning to a new level by leveraging visual transformers. In this article, we’ll dive into the world of DINOv2 and explore its key concepts, methodology, and potential applications.
The Rise of Visual Transformers
Before delving into DINOv2, it’s crucial to understand the foundation upon which it is built: visual transformers. These are neural network architectures that apply the transformer architecture, originally designed for natural language processing, to images. The fundamental idea is to divide an image into patches, treat these patches as tokens, and use a transformer to process them as if they were words in a sentence.
DINOv2 Methodology
DINOv2 is not just another self-supervised learning method; it’s a groundbreaking approach to the unsupervised pre-training of visual transformers. Unlike traditional supervised methods, DINOv2 doesn’t require labeled data to learn object recognition or segmentation. Instead, it focuses on training a neural network to understand and represent the underlying structure and features of images.
Key Components of DINOv2
Student-Teacher Architecture: DINOv2 employs student-teacher architecture, a concept borrowed from knowledge distillation. However, in this case, both the teacher and student networks have the same architecture. The teacher network is constructed from the student network through an exponentially moving average mechanism.
Augmentations: To generate diverse views of the same image, DINOv2 uses various data augmentations. These augmentations include flipping, color jitter, and cropping, both global (covering more than 50% of the image) and local (covering less than 50% of the image).
Centering and Sharpening: DINOv2 uses two techniques, centering and sharpening, to stabilize and enhance the learning process. Centering involves subtracting a running average of representations, promoting consistency among different views of the same image. Sharpening refers to adjusting temperature parameters in softmax functions to make the student network’s predictions more focused.
Training and Benefits
During training, DINOv2 encourages the student network to produce consistent representations for different augmentations of the same image. This process facilitates the learning of meaningful image features without the need for labeled data. The resulting representations exhibit remarkable properties, such as clustering images of the same class and grouping similar classes together, making them valuable for tasks like image retrieval and classification.
FACET Benchmark New
FACET (Fairness in Computer Vision Evaluation), a new benchmark for assessing the fairness of computer vision models, was recently unveiled by Meta. The AI team at Meta claimed that fairness benchmarking in computer vision was traditionally “hard to do.”
“The risk of mislabeling is real, and the people who use these Artificial Intelligence systems may have a better or worse experience based not on the complexity of the task itself, but rather on their demographics,” wrote Meta in a blog post. FACET is only used to evaluate research. Commercial AI model training cannot be done with it.
It is made up of 32,000 photos with 50,000 persons in them that have been annotated by skilled humans for demographic characteristics. These include the perceived gender presentation, extra physical characteristics including perceived skin tone and haircut, and occupational and activity classes like basketball players, guitarists, or doctors, among others. 69000 masks from the SA-1B dataset, which was used to create the Segment Anything model, are additionally labeled for people, hair, and clothing in FACET. To manually annotate the data pertaining to demographic attributes, Meta claimed to have hired “expert reviewers”. They created bounding boxes for the individuals in the picture and assigned certain classes to them based on their jobs and pastimes.
The test, according to Meta, will be used to determine whether concerns about model performance are connected to human characteristics, such as whether detection models have trouble identifying people whose skin appears darker.
“FACET can be used to probe classification, detection, instance segmentation, and visual grounding models across individual and intersectional demographic attributes to develop a concrete, quantitative understanding of potential fairness concerns with computer vision models,” added Meta.
Applications and Potential
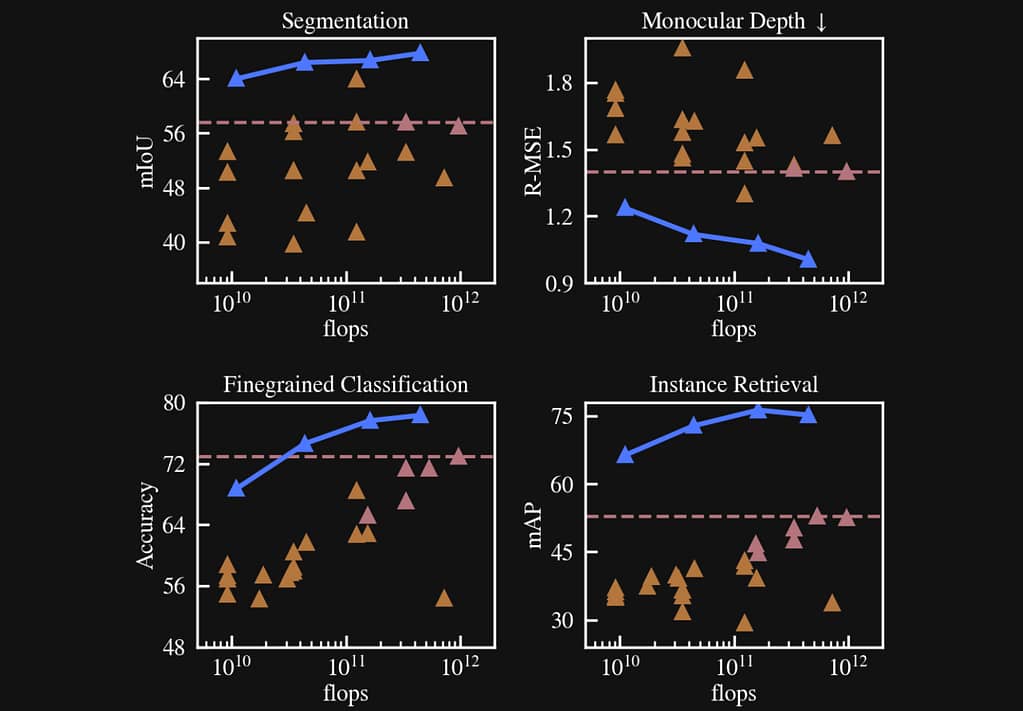
DINOv2’s contributions extend beyond self-supervised learning. The representations it produces empower various downstream applications. These include image retrieval, linear classification, and even zero-shot classification. DINOv2’s capabilities demonstrate that it could be a significant step forward in unsupervised representation learning for images.
DINOv2, with its innovative approach to self-supervised learning using visual transformers, offers a promising avenue for training neural networks without the need for labeled data. Its ability to produce powerful image representations has the potential to reshape the landscape of computer vision and AI research. As we continue to explore the possibilities of DINOv2 and similar approaches, we may unlock new horizons in understanding and harnessing the visual world.